Netlab™ introduces a new form of
synapse (based on
multitemporal connection-points) called a
multitemporal synapse, it is sometimes hyphenated as
multi-temporal synapse.
It fully solves
the stability-plasticity problem, and eliminates
catastrophic forgetting in networks utilizing any training algorithm. It achieves this by providing multiple connection-weights per a connection, where each
weight within the connection can be set to
learn and
forget at a different rate from the others. That is, a separate
learning method and
forget process can be specified for each of the multiple weights used to make up a single given connection between two objects (see diagram below). During signal propagation each input signal is modulated by the combined values of all the connection-weights in its synapse.
Each connection consists of the following three novel characteristics:
- Each connection between two entities consists of multiple, distinct, connection-weights,
- Each of the weights associated with a single connection can learn and forget at a different rate, and
- Connection-strengths (represented by weights) can learn from other weights at the same connection.
The following three sections provide a little more detail about these characteristics:
• Each connection between two entities consists of multiple, distinct, connection-weights
By employing multiple
connection-strengths (represented by
weights), each having distinct
acquisition and
retention times, individual synapses are able to strengthen, and
continuously forget, at multiple different rates. This, in turn, allows the system to continuously learn and adapt to each new present-moment that happens along. The idea works by embracing forgetting as simply an inevitable—and even necessary—part of continuously adapting to present-moment details.
• Each of the weights associated with a single connection can learn and forget at a different rate
Slower-learning (or permanent) weights learn from their faster counterparts at the same connection-points (see below). Because of this, they are able to be trained gradually, over time, by many
different present-moment experiences.
The
fast-learning weights, on the other hand, quickly learn to respond to each present moment as it is encountered and, just as quickly, forget those lessons when they are no longer needed.
• Connection-weights can learn from other weights at the same connection
Any
weight value can be adjusted by any means, such as
influence learning or classic back-propagation. That said, a learning algorithm called
weight-to-weight learning has been developed specifically for multitemporal synapses. This learning method uses one or more of the multiple
weights associated with a connection to produce a
learning factor, which is then used to train another
weight at the same connection-point (e.g., in the same
synapse).
This allows, for example, a connection to be specified with a long-term (slow-learning) connection-strength, which will learn directly from a fast-forming connection-strength at the same
synapse. The fast-forming connection quickly converges on transient responses, and just as quickly forgets them. The long-term weights gradually absorb training from the fast-forming weights each time the fast weights converge on a new (to them) response. To the long-term, slower learning weights, these quickly learned weight-sets can be thought of as flash-cards, holding the proper response to the current situation. Just as traditional
ANNs are taught, gradually, on a set of exemplars, so too, are the slower weights in multi-temporal connection-points.
|
In this fashion, slower weights are able to absorb the various encounters that come and go on the fast weights in an interleaved fashion, and at a slow rate. They are, therefore, continuously, gradually, trained on an interleaved repertoire of multiple present-moments as those present moments pass. This is very similar to how the experiences would be trained in a traditional ANN, In the general case, however, the repertoire-sequence seen, and slowly trained, by slow weights will be the most recently relevant sub-set of all present moments experienced.
|
|
. . . . . . .
Discussion
Multi-temporal connections intrinsically provide two capabilities to a running neural network that completely overcome, and solve
the stability-plasticity problem, as well as the problem of
catastrophic interference, thus, allowing for a network that is able to
continuously learn while it interacts with its milieu.
- On the response side, short-term weights allow the network to quickly form precise behavioral responses to situations that are novel in details, but have general similarities to, situations experienced in the past.
- On the learning side, short-term weights also intrinsically process ongoing experiences in such a way as to provide an interleaved set of exemplars, in a flash-card-like fashion, to the slow weights, which can continuously train them in real time.
More detail on each of these follows:
1. The additional short-term weights allow the network to quickly form fine-grained responses to situations that are novel in details, but broadly similar to, situations that have been experienced in the past. — At first glance this may sound no different than traditional
ANNs, but in fact, it allows long-term weights to be free of the clutter normally required to store fine-grained response details. The kind of information that makes it (slowly) into the slowly adapting (long-term) weights can best be thought of as a set of vague beginnings of responses to stimuli, which were learned from stable values that formed on the fast weights, many times over the life of the network. Because of their incomplete nature, many of these responses can be maintained in long-term connection-strengths with little interference. During
signal propagation, the long-term weights act as a prompting agent, immediately starting a network response that is a similar —but residual— representation of responses to many similar situations that had been experienced in the past. The short-term weights start from zero at each new encounter (simplified). They will be prompted, by responses stored in long-term weights, in a direction that has a good chance of being
nearly the correct way to start responding.
2. The additional short-term weights provide a continual presentation of training exemplars to the long-term weights, in an interleaved, flash-card-like fashion. — This allows for the slow weights to be
continuously trained in the course of the network's normal interactions with its milieu. Because fast-adapting weights quickly learn a detailed response to the current situation, and just as quickly decay back down to zero, they have the effect of presenting multiple training exemplars in real time-- to be slightly learned by the long-term weights. This allows new experiences to be added to the slow weights, while existing response-vectors are reinforced by situations that are similar to previously learned experiences.
. . . . . . .
Fast learning/forgetting weights will re-learn very quickly
In the absence of any new experience, the residual connection-strengths maintained in the fast weights quickly decay to zero. Typically, after only a minute or less with no input, the fast weights will be totally blank. No residual connections—left over from past experiences—will remain.
Also, keep in mind that the
weight-to-weight learning in this scenario is one-way, from fast to slow weights only. That is, slow weights learn from the values on fast weights when they exist, but fast weights are not directly affected by values stored in slow weights. Nonetheless, in spite of starting with a totally blank slate for each experience, the fast weights will learn and adapt much faster when the present-moment is similar to past experiences. This occurs tacitly, even though the slow-learning weights have no direct effect on the values of the fast weights.
Two underlying mechanisms are primarily responsible for this behavior.
- The Hand-Over-Hand Effect
. . . . .
Consider, first, that each time the fast weights converge on an experience, a small portion of the converged state of the fast weights is transferred into the slow-learning weights at the same connection-points via weight-to-weight learning.
To the fast weights, which start out blank and quickly ramp up, every situation is always new, and never before seen. Their job is to quickly adapt to it, and they are able to do so with prompting from past residual responses maintained in the slower-learning weights. The responses caused by the slower weights, on the other hand, serve only to guide the fast weights with gentle prompting in the form of starting-responses. This is what facilitates quick adaptation of the fast weights to the current experience.
Note that the slow-learning connections, are, paradoxically, fast-responding. That is, they will immediately produce the blunt, anoetic beginnings of a correct response the instant similar stimuli first arrive (spread over many connection-points). When stimulated, they immediately convert a given set of familiar stimuli to a starting response signal.
To the fast-learning connection-weights, the residual responses driven by the slow weights is like a teacher, using hand-over-hand prompting of the student along a correct path. This, in turn, facilitates much faster re-learning. Though the prompting from slow-weight-facilitated responses is tentative, and incomplete, it is complete enough to allow the blank-slate of the fast weights to quickly adapt to the new situation.
Another way to think of the information in the long-term weights is that it provides response mnemonics, which helps the short term weights quickly adapt to immediate details.
- Freedom from Catastrophic Interference Effects
. . . . .
Another consideration that contributes to fast acquisition times on the fast weights is that they do not have to be concerned with over-writing or interfering with previously learned lessons. They are wiped clean very quickly once the need to respond to a given experience ends. They only need to quickly learn whatever response is currently before them, without concern for overwriting past experiences, so the learning-rate can be set to be very fast.
Interference is mitigated in slow weights in a fashion that resembles how it is mitigated in traditional ANNs during their training stage. In traditional ANNs this is accomplished during training by employing a slow learning rate, which moves weight values only slightly on each interleaved presentation of an exemple stimulus/response in the training set. With multitemporal synapses, however, this process can occur continuously in slow weights, while the organism interacts with its environment via its fast weights.
. . . . . . .
The Benefits Are Significant
Multitemporal synapses impart a variety of benefits. The problem of
catastrophic forgetting, for example, is eliminated because, to slower (or permanent) weights, each "present-moment" is seen as one of many training-exemplars, in a randomly repeating, interleaved, set of exemplars. That is, fast-learning weights respond to each new present-moment as a blank neural network, which is quickly, and completely trained to respond as a single, isolated, response mapping. Because present-moments are quickly forgotten in fast weights, many different present-moments are learned, and presented to the slower connection-weights over time, allowing all the present-moments to be gradually trained as a complete, interleaved, set.
Structurally, this is indistinguishable to how conventional networks must be trained on a complete set of desired response-mappings. The conventional practice is for each desired response in the set to be trained gradually, over many successive iterations of the entire set.
There are some important differences, however.
In conventionally trained neural networks, while the set of all training exemplars may be shuffled between each training-cycle, the stimuli-response mappings themselves are always identical, every time they are presented. For example, conventionally, whenever stimulus/response-#1 is seen in the random training rotation, it will be identical to how it looked the last time it was presented.
In multitemporal synapses, however, when stimulus/response-#1 comes up a second time in the rotation, it will be slightly different than it was the first time it was presented. This is because, while similar, no two present-moments experienced in the wild will be exactly the same. Nor will the appropriate response.
~~~~~~~
Diagram
The following diagram is taken from Figure 5.1 in the book. It shows the structure of multitemporal synapses schematically.
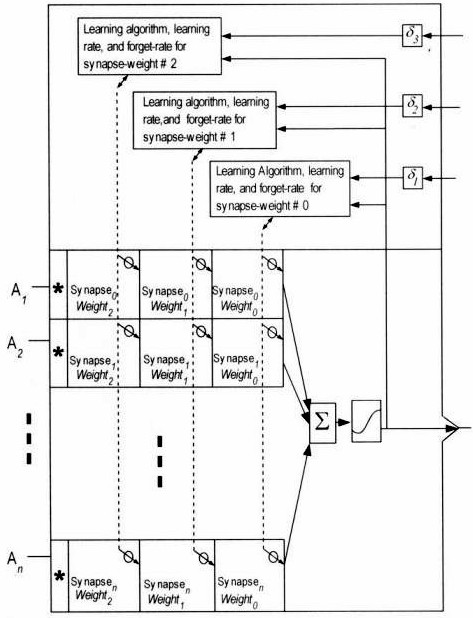
In the above diagram, a neuron is depicted with three
weights, representing three distinct
connection strengths, per a
synapse. Each synapse
weight can have its own rate of
learning and its own (optional)
forget rate. Each synapse-weight thus becomes a class of weight that is replicated over multiple input synapses. Conceptually, this can be visualized as forming synapse-weight
layers across the multiple inputs.
~~~~~~~
Underlying Biology
When considering the underlying biology that led to these algorithms, the name "multitemporal
synapse" may be a bit misleading. It is probably a much better fit to refer to the underlying concept as "multitemporal
connection points."
In biological brains, there are a variety of known mechanisms that facilitate timing differences in the formation and decay of connections. Many of these have been observed at the level of individual synapse. Many others can be based on connection formation/retention characteristics between different neurons, and different neuron types. Relatively longer-term connections may be formed (i.e., more slowly) based on
pathfinding, or on the formation of new synapses from an existing axon.
To summarize, in biological brains, there are many known mechanisms, which are responsible for differences in the amount of time it takes to form, and retain, a connection between any two entities. Even based on the limitations of what we currently know, only a small sample has been presented here.
~~~~~~~~~~~
An Important Distinction: Propagation vs Adaptation (reactive vs adaptive signaling)
As someone who enjoys learning about
Neural Networks, for the longest time I naturally conflated
signal propagation (the signals produced by neurons as they responded to a given situation) with
adaptive signaling (the changes occurring to connection strengths that change
how neurons react to those propagated
reactive input signals).
It took me a while to realize the distinction between these two things, and the necessity for them to be considered separately. I've noticed this tendency to not separate these two types of Neural-Network state-changes (and changers) in others who are passionate about
ANNS as well. There are times when these two agents are very closely related. In
Influence Learning for example, adaptive influences are created
as reactive signals are propagated. Even in this case, and perhaps especially in this case, a firm grasp of the separate and distinct natures of the two mechanisms is needed to fully analyze how the two mechanisms are relating to each other as the Neural Network is interacting with, and adapting to, its milieu.
In
multitemporal connections, the temporality is on the adaptive side (not the reactive side). That is, the temporality is in how quickly or slowly the connections are formed in response to the needs of the current situation (the reactive signaling) and how quickly or slowly those connections are lost once the instigating situation has subsided.
~~~~~~~~~~~
Spit-balling
I'm not sure about this, but sometimes it makes sense to use an existing well-understood concept as a way to metaphorically relate, and better understand, a new one. Of course, that requires that the metaphor be apt, and tightly track the new concept. So . . . queue theory
seems to be a good metaphorical match to temporal adaptation. It remains to be seen if that assumption holds up.
- FILO: Quickly adapts/learns, slowly forgets. (fast-learning, slow-forgetting connection-strengths)
- FIFO: Quickly adapts/learns, quickly forgets. (fast-learning, fast-forgetting connection-strengths AKA fast weights)
- LIFO: Slowly adapts/learns, quickly forgets. (slow-learning, fast-forgetting connection-strengths. Useful?)
- LILO: Slowly adapts/learns, slowly forgets. (slow-learning, slow-forgetting connection-strengths AKA slower weights)
. . . . . . .
Some History
As a non-academic person I tend to have a great deal of trouble in establishing priority. These patents have been the latest attempt to address that concern. Sadly, they have not worked as well as hoped.
- 22-March-2007 — Patent application #11/689,676 filed (as a CIP to an earlier application).
- 08-March-2011 — Patent # 7,904,398 awarded
. . . . . . .
Resources
- Related Background
- The Fantastic Array of Neuroplasticity Mechanisms
From Dr. Jon Lieff's excellent blog. A discussion of the many different mechanisms employed for making, strengthening, weakening, and removing connections in the brain.
- Discovery of a new mechanism for controlling memory
More proteins discovered.
- Researchers discover the key to long-term memory
Hasn't this been known (or at least strongly suspected) that CaMKII played this role in memory (e.g.)?
- The Rhythm That Makes Memories Permanent
"Every time we learn something new, the memory does not only need to be acquired, it also needs to be stabilized in a process called memory consolidation."
- DNA Methylation Adjusts the Specificity of Memories Depending on the Learning Context and Promotes Relearning in Honeybees (12-Sep-2016)
A very nice article describing some of the biological underpinnings of the behavioral observations that led to multitemporal synapses.
- Hold that thought - Slowly but surely, scientists are unveiling the complex chemical underpinnings of memory
Long and short term memory involve a complex interplay of changing receptor efficiency, formation of actin, and new receptors, pathfinding, and other factors. This 2007 paper provides a very nice overview of some of the biological understanding that led to multitemporal synapses.
- Long-term memories are maintained by prion-like proteins
Filling in our understanding with more observations.
- MicroRNA Regulation of the Synaptic Plasticity-Related Gene Arc
- Slide, showing some of the biological underpinnings.
These papers are always presented as new and revolutionary, but these mechanisms were clearly being discussed and speculated about in at least one two-decades-old textbook.
- Clive Wearing - The man with no short-term memory
- Related Blog Entries
. . . . . . .
Plagiarism
- Mathematical model helps explain how the brain forms new memories without wiping out old ones
This.
- CLA
And This. . . Funniest thing about this is their claim that they came up with this revolutionary intellectual contribution way back in 1995? Yes, they are only reporting it as news now (19 June 2016), but, they insist, they discovered it way back in 1995.
- Complimentary Learning Systems — CLS
What else can one do, but document the behavior, and hope the truth eventually prevails?
- many more examples to follow...
 Stand Out Publishing
Stand Out Publishing