About:
Exploring new approaches to machine hosted
neural-network simulation, and the science
behind them.
Your moderator:
John Repici
A programmer who is obsessed with giving experimenters
a better environment for developing biologically-guided
neural network designs. Author of
an introductory book on the subject titled:
"Netlab Loligo: New Approaches to Neural Network
Simulation". BOOK REVIEWERS ARE NEEDED!
Can you help?
The book on the Netlab project often returns to the notion that learning is merely a form of adaptation and that, conversely, adaptation is merely a form of long-term learning. This, in turn, all fits under the umbrella notion that memory is behavior.
The idea that learning is adaptation is learning is forwarded as a possibility, mainly as a better means of discussing the concepts. This (in my opinion) provides a clearer and more converged understanding of how memory works in biological organisms. This could be very wrong, of course, so it's important to describe it properly. That way it, and not a straw man, can be critiqued. This article represents one such attempt to properly describe it. . .
Batesian Mimicry
Batesian mimicry is when a non-noxious/non-poisonous plant or animal projects the appearance of a poisonous plant or animal, allowing it to avoid being eaten by predators.
Those predators, goes the logic, which have partaken of the poisonous organism and survived, would have become very sick, and would have learned to avoid ingesting anything that appears to be that organism in the future. This will include those organisms who are not poisonous, but merely look, or act, like the poisonous organism.
This article provides a layman's-level discussion of neural network technology within the framework of a sketchy historical sequence. Neural networks are described while presenting an overview of just one of the many routes taken by the field in the last half-century or so.
It is not for those interested in a full history of neural networks (i.e., connectionism). It is just a quick backgrounder, which should suffice to give readers a little bit of perspective into how we got from "there" to "here." The actual history of this field is storied, and sometimes even checkered and controversial. I highly recommend to anybody who is interested, that you get a good book or two on the subject.
This entry will also serve as a place to accumulate links to resources and information on the subject of neural networks and their history at this layman's level.
Scientists at UC Berkeley have taken brain scans of subjects in an fMRI machine while they watched a movie clip. They then reconstructed the movie the subjects were watching using only the brain scan data, and a database of 18 million seconds of random video gleaned from the web.
First, they used fMRI imaging to measure brain activity in visual cortex as a person looked at several hours of movies. They then used those data to develop computational models that could predict the pattern of brain activity that would be elicited by any arbitrary movies (i.e., movies that were not in the initial set). Next, they used fMRI to measure brain activity elicited by a second set of movies that were also distinct from the first set. Finally, they used the computational models to process the elicited brain activity, and reconstruct the movies in the second set.
The amount of new understanding this could allow us to gather about mind-brain correlates and first person knowledge should be considerable. If this lives up to the hype, a lot of new research ideas should come out of it. Keeping fingers crossed here.
In the above clip - the movie that each subject viewed while in the fMRI is shown in the upper left position. Reconstructions for three subjects are shown in the three rows at bottom. All these reconstructions were obtained using only each subject's brain activity and a library of 18 million seconds of random YouTube video that did not include the movies used as stimuli. The reconstruction at far left is the Average High Posterior (AHP). The reconstruction in the second column is the Maximum a Posteriori (MAP). The other columns represent less likely reconstructions. The AHP is obtained by simply averaging over the 100 most likely movies in the reconstruction library. These reconstructions show that the process is very consistent, though the quality of the reconstructions does depend somewhat on the quality of brain activity data recorded from each subject. [source: Gallant Lab (see resources below)]
A neural network innovation described in the book: Netlab Loligo has been awarded a patent (#7,904,398). — Of the innovations described in the book, it is the second to receive letters patent (so far ). The patent is titled:
“Artificial Synapse Component Using Multiple Distinct Learning Means With Distinct Predetermined Learning Acquisition Times”
Patent titles serve mainly as an aid for future patent searchers. The patented innovation, along with the underlying concepts and principles that led to it are described and discussed in the book, where they are simply referred to as “Multitemporal Synapses.”
The primary advantage imparted by the innovation is that it gives adaptive systems a present moment in time. This allows them to quickly and intricately adapt to the detailed response needs of their present situation, without cluttering up long term memories with the minute details of those responses.
Multitemporal Synapses
This is a blog entry here that tries to describe Multitemporal Synapses. When time permits, I will try to provide a new blog entry with a clearer explanation using book excerpts (P.S. see above entry). It will be specifically geared to laymen. If you are interested, please subscribe to the feed.
Influence Learning Gets A Patent
Influence Based Learning was the first of Netlab's innovations to be granted a patent. This latest patent makes two (and counting, stay tuned).
The Netlab development effort has led to a new method and device that produces learning factors for pre-synaptic neurons. The need to provide learning factors for pre-synaptic neurons was first addressed by backpropagation (Werbos, 1974). The new method differs from backpropagation in that its use is not restricted to feed-forward only networks. This new learning algorithm and method, called Influence Learning, is described here and in other entries in this blog (see Resources section below) .
Influence Learning is based on a simple conjecture. It assumes that those forward neurons that are exercising the most influence over responses to the immediate situation will be more attractive to pre-synaptic neurons. That is, for the purpose of forming or strengthening connections, active pre-synaptic neurons will be most attracted to forward neurons that are exercising the most influence.
Perhaps the most relevant thing to understand about this process is that these determinations are based entirely on activities taking place while signals (stimuli) are propagating through the network. Unlike backpropagation, there is no need for an externally generated error signal to be pushed through the network, in backwards order, and in ever-diminishing magnitudes.
Support In Biological Observations
While influence learning in artificial neural network simulations is new, it is based on biological observations and underpinnings from discoveries made over twenty years ago. One of the biological observations that led to the above speculation about attraction to the exercise of influence was discussed briefly in the book The Neuron: Cell and Molecular Biology.
An experiment described in that book shows what happens when you cut (or pharmacologically block) the axon of a target neuron. In that experiment the pre-synaptic connections to the target neuron began to retract after its axon was cut. That is, the axons making presynaptic connections to the modified neuron went away when it no longer made synaptic connections to its own post-synaptic neurons.
The book also described how, when the target neuron’s axon was unblocked (or grew back), the axons from presynaptic neurons immediately began to reform and re-establish connections with the target. Based on these observations, the following possibility was asserted.
"...Maintenance of presynaptic inputs may depend on a post-synaptic factor that is transported from the terminal back toward the soma."
The following diagram depicts these observations schematically.
A set of constructs and methods introduced and described in the book: Netlab Loligo will improve the ability of systems constructed with them to adapt to current short-term situations, and learn from those short-term experiences over the long term.
A New Learning Theory That Predicts A “Present Moment”
How do we, as biological organisms, manage to keep so much finely detailed information in our brains about how to respond to any given situation? That is, how do we manage to keep countless tiny intricacies stored away in our “subconscious” ready to be called upon at just the right time, right when we need them in the present moment?
According to this theory of learning, the answer to that question is: We don't.
Instead, our long term connections—those that immediately drive our responses at all times—are only concerned with getting us started in any given “present.” Responses stored in long-term connections start us along a trajectory that makes it easier for us to learn whatever short-term, detailed responses are needed for any given detailed situation.
Connections that drive short-term responses, on the other hand, form spontaneously in-the-moment, and quickly adapt to whatever present situation we currently find ourselves in. Just as significantly, connections driving short-term responses tend to dissipate as quickly as they form. This theory essentially says that each connection in the brain that drives responses (physical or internal) includes multiple distinct connection strengths, which each increase and decrease at different rates of speed.
How It's Done
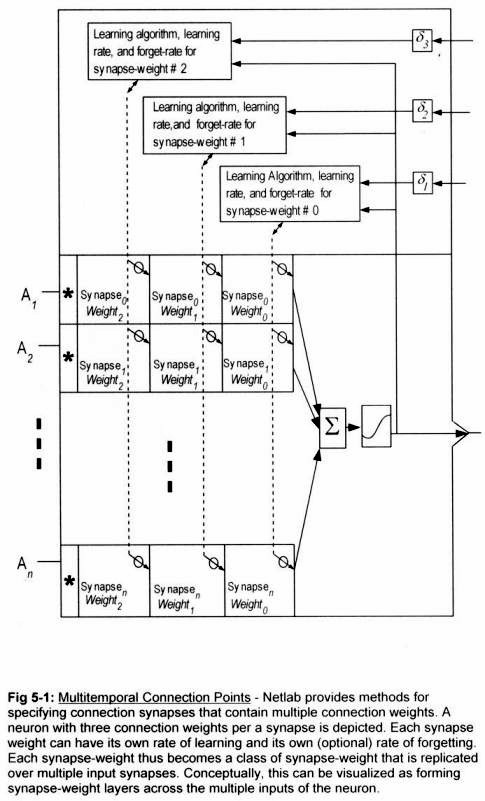
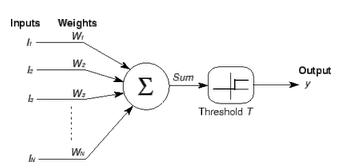
Multi-temporality is achieved in Netlab's simulation environment by providing multiple weights per a connection point (i.e., synapse), which are referred to as Multitemporal[Note 1] synapses. Multitemporal synapses employ multiple weights. Each of the multiple weights associated with a given synapse represents a connection strength, and can be set to acquire and retain its strength at a different rate from the others. The methods also specify Weight-To-Weight Learning, which is a means of teaching a given weight in the set of multiple weights, using the value of other weights from the same connection. Together these constructs provide all the functionality required to model the theory of learning discussed above.
Following is a graphic excerpted from the book: Netlab Loligo, which shows a neuron containing three different weights for each connection point. Each weight is given its own learning algorithms, with its own learning-rate, and forget-rate.
Stanford University School of Medicine has developed a relatively simple new imaging technique that provides a very exact way to capture the synapses of a connectome with pinpoint 3D positional accuracy, and considerable contextual resolution.
Stanford has performed a study (see below), which was admittedly done primarily just to showcase the new technique. That said, the study managed to produce a very impressive new find.
“
In the course of the study, whose primary purpose was to showcase the new technique’s application to neuroscience, Smith and his colleagues discovered some novel, fine distinctions within a class of synapses previously assumed to be identical.
”
 Stand Out Publishing
Stand Out Publishing


 ). The patent is titled:
). The patent is titled: