Early neural networks consisted of a single layer of perceptrons. Like their McCulloch-Pitts predecessors (1943), they had binary outputs, but now they had a new way to learn (Rosenblatt 1958). Their
weights could be altered by a simple
learning rule. These worked very well for basic classification and mapping problems, especially, where the solution was not going to be evident in the data-set that was available at design-time. You could train them to map a set of example training input patterns to your desired output patterns, and voila! You have a system that performs your pattern mapping. This may not seem that exciting in and of itself, but once trained, your network will perform mappings for similar patterns that were not included in the original training set. In other words, your network will generalize from the patterns it was trained on, to new, never-before-experienced patterns, and generate appropriate responses.
Further advancements came in Widrow and Hoff's Adaline (and later, Madaline
[1]) networks. Eventually, the binary output limitations of earlier models also fell away. Those binary designs seemed to be merely an early misinterpretation of how
action potentials are used within biological neurons to represent signals. Action potentials produced by neurons are all-or-nothing pulses, but the pulses themselves turned out to be shape-, phase- and frequency-modulated representations of analog levels.
These new developments, along with the intrinsic ability of neural networks to generalize, produced a lot of excitement about the new neural network field. As stated, the excitement came mainly from the fact that you could train a system to respond in a desired way, and the system would respond to previously untrained problems in a way that was similar.
These were great innovations, but the single layer networks of the time were shown, in a book by Minsky and Papert
[2], to have some serious problems. They could not perform any mapping that included an exclusive-OR component (this,
OR that, but
NOT both). Since many pattern-responses in nature require such a mapping, this limitation was clear evidence that something new remained to be discovered.
It probably should be noted here (with cautions against conclusions about the motives of others) that some histories claim that Minsky and Papert's primary goal was to drive research funding away from neural networks, and into the field of computational artificial intelligence. If this was their motivation, they may have succeeded, but the connectionists weren't giving up.
To solve the linear separability issues alluded to in the exclusive-OR problem, the connectionists realized that a network would need to be constructed with multiple layers of neurons. There would need to be output neurons that provided the desired results, as well as hidden neurons feeding them. The
hidden layers would be taught to perform intermediate functions needed to solve exclusive-OR.
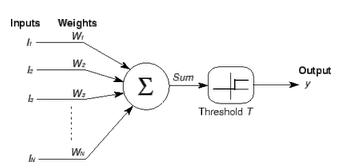
Output neurons could be taught in the same way they had always been taught, by determining the difference between the desired output and their actual output, then using that difference-value to make weight adjustments. The neurons in the "hidden" layer, however, presented a problem. If a neuron is "hidden" behind another neuron, how can you know what its desired output value should be?
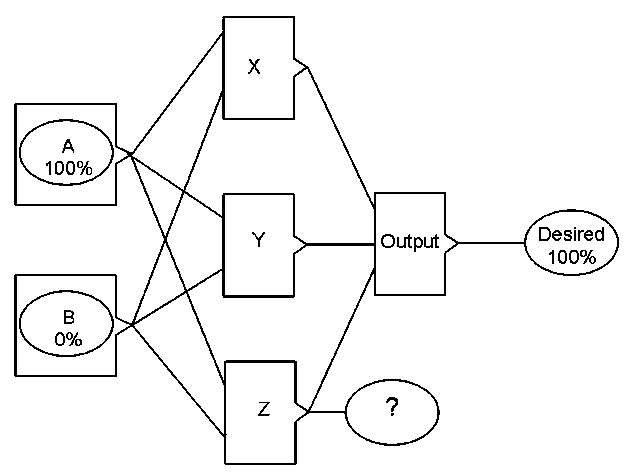
| | Hidden Desire — The above diagram shows a neural network that can be trained to perform the exclusive-OR function (A or B, but not both). — — With the input-values shown for A and B, we know that the desired value on the “Output” neuron should be 100%. But what should the desired value be on the output of neuron Z? | |
You know what value you want to see on your output neuron, and can determine the difference between that desired value, and the value that it is currently producing. The difference between these two values is the error value that is used to make changes to the neuron's weights.
But what do you do if your neuron is not an output neuron? How can you determine what its error value should be if you don't know what its desired output value should be?
Though Minsky's exclusive-OR problem was what drove people to the realization that multiple layers would be needed, the problem of how to train those layers that were "hidden" simply drove people crazy. Then, along came a guy named
Paul Werbos, who was able to assimilate and apply a new idea in control theory. One which he had learned directly from the guy who developed it, his professor, Dr. Yu Chi Ho. Werbos applied Ho's theories directly to the new discoveries and criticisms coming out of the "Ai" field. His idea would later come to be known as
"The Back-Propagation Learning Algorithm."
Using Werbos's new algorithm, you could train the output neurons by calculating the difference between the desired and actual output-values, just as you always did. The new dimension added by backpropagation was that each output neuron would then propagate an error value back for use by the hidden neurons that were providing its inputs. In turn, the hidden neurons would use those back-propagated error values as a basis for their own error values, which they would use to make their own weight adjustments.
If there was yet another layer of neurons behind the first hidden layer, then the first hidden layer would use back-propagation again, in order to provide an error value for them. In this way, each layer would perform its calculations, and, based on those calculations, it would send an error-value back for use by the neurons that were contacting it.
I know what you're thinking. Werbos didn't invent back-propagation! Well, yes, in spite of some impressive, and sometimes shameless, efforts to marginalize his contribution, it seems he really did.
Just as McCulloch and Pitts produced a first renaissance around neural networks, Dr. Werbos's backpropagation algorithm created a second renaissance. The journals were once again a-buzz with various explanations and applications of neural networks trained using the back propagation algorithm. In these journals, you would have seen the networks promoted as having been discovered by other names, but the original idea was Werbos's.
Early on, there were many new questions raised that needed to be answered about the many cool and interesting things you
could do with back-propagation neural networks. There was way to much to discover to worry much about the shortcomings.
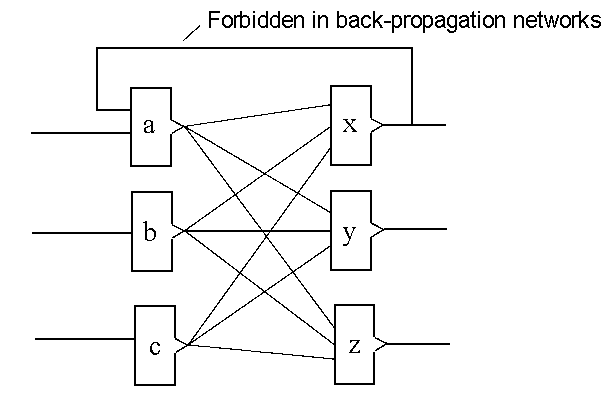
Besides, unlike the exclusive-OR problem, backpropagation's shortcomings were obvious. You didn't need a rigorous analysis to see that they were only good for feed-forward networks. Why? Because of the nature of the backpropagation algorithm itself. In order to produce a backpropagation value to send back to pre-synaptic neurons, a neuron must first produce its
own weight-adjustment value. To produce its own value, it has to use the backpropagation values that have already been calculated by the
post-synaptic neurons with which it makes contact.
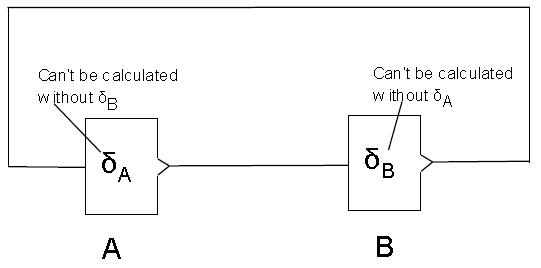
| | Round and round we go — In order to calculate the backpropagation value for a neuron, you need the backpropagation value for all the neurons it connects to. In order to calculate this value for A (δA) in the above example, you need the backpropagation value from B (δB). In order to calculate δB, you need the backpropagation value from A, But A’s value (δA) can’t be calculated until you calculate B’s value (δB). | |
Early on, backpropagation's inability to support feedback didn't seem to be a serious limitation. After all, you didn't need feedback to solve exclusive-OR. Even if there were found to be a need, in spite of the exclusive-OR mapping being solved, the dream was in place. If hidden layers of neurons could be trained, then some way to improve upon backpropagation to make it capable of handling feedback should be a snap. Most (including me) thought that it would be just a matter of adding some computational extensions to the existing back-propagation algorithm to make it able to handle feedback smoothly and intuitively.
So the problem was easily understood. In order to calculate the neuron-level error value for the current hidden-layer neuron, it is necessary to have first calculated the same error value for each post-synaptic neuron to which the current neuron is connected. This is what restricts back propagation to feed-forward-only networks.
Studies of biological neural networks have demonstrated that numerous and diverse signal feedback paths and mechanisms exist in biological organisms
[3]. These mechanisms include direct signaling carried on
afferent axons back through networks whose outputs, in turn, affect the
efferent signal flows. Signal feedback in biological organisms also occurs through a variety of chemical signaling mechanisms carried directly through glial cells (those cells that support neurons in biological brains), and through the bloodstream from a variety of intra-organism sources. Finally, signal feedback mechanisms occur tacitly in biological organisms through the senses that carry afferent information about causal effects that efferent signals have had on outside world environments.
In biological organisms
[4], the concepts of “internal” and ”external” may not represent absolute locations, but instead may allude to a continuum. Simplistically, afferent signaling may begin with senses of external world events caused by motor controls such as muscles. On the other hand, it may be caused by a chain of events that started within the brain and ended up as stimulation to the adrenal gland, which in turn produces an afferent chemical signal that causes the brain to retain more experiences. The later case shows that external signals can be generated by a feedback loop that is outside of the brain, but never leaves the organism.
Such loops may occur entirely inside the brain, or may just get out to the point of generating scent signals via the organism's own sweat glands, which are then sensed and have an afferent effect on the network. Much further out, a very complex chain of external events may be affected by the brain and produce effects that are then sensed by the brain via the organisms many senses. In this way, the brain can produce effects on, and correct for, external world events.
To summarize, feedback loops of signals originating in the brain and returning can remain inside the brain, go outside the brain but remain inside the organism, or include causal activities completely outside of the organism.
Backpropagation is an abstraction that encapsulates the detailed mechanisms used in (inferred from) biological networks. It aims to mimic behavior observed in biological neurons in order to better respond to the external environment. Because backpropagation's abstraction of these underlying mechanisms encapsulates the details into its reverse error propagation calculation, it doesn't normally allow them to be broken out and used in combination. In other words, the details of how biological neural networks actually produce changes in their connection strengths are completely incorporated into a single, conceptual, black-box that is the backpropagation algorithm.
The advantage of this level of abstraction is that backpropagation fully encompasses and mimics the concepts of positive and negative reinforcement learning within its calculations. This frees the network designer from having to consider such details when designing a neural network. The disadvantage can, in some sense, be expressed by simply parroting the advantage. The designer must accept back propagation's abstract interpretation of the underlying concepts, and the observed behavior that it encapsulates. There is little (if any) flexibility in the details of how such mechanisms can be employed by the neural network to effect changes in its connection weights.
A variety of methods to work around back-propagation's feedback limitation have been tried with varying levels of success. The following provides example.
Back Propagation Through Time (BPTT) — This has been used to partially mitigate backpropagation's limitation on feedback. A simple means of applying standard back propagation in a neural network that would normally employ feedback (a recurrent neural network) is called "Back Propagation Through Time" or BPTT. It accommodates the use of the standard back propagation algorithms by unfolding the time sequence that would normally be present in a recurrent network in order to get around back-propagation's restriction on feedback. The essence of BPTT is that it unfolds the discrete-time recurrent neural network into a multilayer feed-forward neural network (FFNN) each time a sequence is processed. In effect, the FFNN has a separate hidden layer for each "time step" in the sequence. It should be noted that the feed-forward-only restriction of back propagation has not been overcome in BPTT. Instead a clever means of removing the feedback from a recurrent network has been implemented so that the back propagation learning algorithm can be used along with its inherent restriction.
Real Time Back propagation (RTBP) Permits Feedback But Only Of Output Neurons — Real time back propagation, or RTBP, permits feedback from output layer neurons to output layer neurons only. As shown in the above calculations, each of the output neurons’ error values are calculated directly by subtracting an expected (desired) output from the actual output of each neuron. Since there is no need to use the calculated error values from post-synaptic neurons in order to calculate these error values, this tightly restricted form of feedback for this one layer can be permitted in RTBP networks. There is still no way to produce the feedback of complex afferent signal flows seen in biological neural networks. Any feedback from the outputs of hidden neurons to themselves, or to neurons even further back would break the learning algorithm. This is because, for all but the output neurons, the back propagation learning algorithm requires that error values be calculated for all post-synaptic neurons before the error value for the current neuron can be calculated.
Alternatives to Back Propagation That Allow Feedback Will Usually Strictly Dictate Specific Network and Feedback Structures — Alternatives to back propagation neural networks have been conceived in an effort to produce networks with some rudimentary forms of feedback (
Douglas Eck, University Of Montreal, Recurrent Neural Networks— A Brief Overview, 1-October-2007). These generally rely on very strictly prescribed feedback topologies and complex feedback functions to achieve networks with recurrent characteristics. While the recurrent character of the brain is abstractly emulated in these schemes, the ability to design neural networks with the complex and varied feedback structures observed in connected networks of biological neurons is poorly addressed or not addressed. Other forms of networks that permit strictly defined feedback will limit the network to a single layer, or to no more than two layers.
Influence based learning, or just
influence learning, permits neurons to learn from forward-connected (
post-synaptic) neurons, without any reverse, sequentially-dependent calculation. One advantage of this (now patented) learning method over backpropagation and derivatives is that it permits neural networks to be constructed with arbitrarily complex signal feedback paths. Further advantages are discussed in the blog entries here that are tagged with
Influence-Learning.
Neural networks are parallel processing networks composed of artificial neurons connected together in a variety of topologies. Neural networks seek to mimic the way biological neural networks are constructed in order to perform computational functions that are similar to cognitive brain functions. One of the goals of this effort has been to provide a generalized adaptive (learning) method, which is capable of supporting artificial neural networks that include complex signal feedback.
Another goal, (though less prevalent historically) has been to provide a learning mechanism capable of continuously
[5] adapting to its environment. Both of these goals have been realized in a new learning method called
influence based learning, which is described in Netlab. In the bargain, the methods provided in Netlab will also work fine for more conventional artificial neural networks that do not employ signal feedback. The resultant capability allows designers to produce artificial neural networks that more closely mimic the complex feedback (as well as traditional feed-forward) mechanisms observed in studies of biological neural networks.
=======
Notes:
- Madaline networks were an early two-layer network architecture with one output unit combining the outputs of multiple parallel Adalines behind it. The combining function was typically (but not always) simply choosing whichever binary state was being output by the majority of Adalines. They also used a majority function to choose which single hidden Adaline to train in a given training cycle. They could be trained to solve the exclusive-OR problem.
- Marvin Minsky, S Papert - "Perceptrons" - 1969
- Levitan, Kaczmarek, "The Neuron,Cell And Molecular Biology," 2002, Oxford University Press, ISBN: 0-19-514523-2
- Paraphrased from my book (Netlab loligo).
- Not merely continual, but continuous. You will sometimes see this referred to in my writing as “constant” learning.
 Stand Out Publishing
Stand Out Publishing


The Netlab development effort has led to a new method and device that produces learning factors for pre-synaptic neurons. The need to provide learning factors for pre-synaptic neurons was first addressed by backpropagation (Werbos, 1974). The new method
Tracked: Jan 07, 20:03
Woo HOOO! Influence Based Learning, one of two new learning methods described in the book Netlab Loligo, has just been awarded a United States Patent. The official title of the patent is: “Feedback-Toler
Tracked: Jan 07, 20:17
It is known that almost all words are metaphorical at their base, and some people (e.g., me) posit that they all are. Some go even further, and say that the sub-language signaling in the brain, which eventually leads to language, is also metaphorical.
Tracked: Jan 07, 20:20