About:
Exploring new approaches to machine hosted
neural-network simulation, and the science
behind them.
Your moderator:
John Repici
A programmer who is obsessed with giving experimenters
a better environment for developing biologically-guided
neural network designs. Author of
an introductory book on the subject titled:
"Netlab Loligo: New Approaches to Neural Network
Simulation". BOOK REVIEWERS ARE NEEDED!
Can you help?
Other Blogs/Sites:
Neural Networks
Hardware (Robotics, etc.)
|
Tuesday, September 7. 2010
Influence learning is one of two new learning algorithms that have emerged (so far) from the Netlab development effort. This blog entry contains a brief overview describing how it works, and some of the advantages it brings to the task of neural network weight-adjustment.
This learning method is based on the notion that—like their collective counterparts—neurons may be attracted to, and occasionally repulsed by, the exercise of influence by others. In the case of neurons, the "others" would be other neurons. As simple as that notion sounds, it produces a learning method with a number of interesting benefits and advantages over the current crop of learning algorithms.
A neuron using influence learning is not nosy, and does not concern itself with how its post-synaptic (forward) neurons are learning. It simply trusts that their job is to learn, and that they are doing their job. In other words, a given neuron fully expects, and assumes that other neurons within the system are learning. Each one treats post-synaptic neurons that are exercising the most influence as role models for adjusting connection-strengths. The norm is for neurons to see influential forward neurons as positive role models, but neurons may also see influential forward neurons as negative role models.
As you might guess, the first benefit is simplicity. The method does not try to hide a lack of new ideas behind a wall of new computational complexity. It is a simple, new, method based on a simple, almost axiomatic, observation, and it can be implemented with relatively little computational power.
Influence Learning is completely free of feedback restrictions. That is, network connection-structures may be designed with any type, or amount of feedback looping. The learning mechanism will continue to be able to properly adapt connection-strengths regardless of how complex the feedback scheme is. The types of feedback designers are free to employ include servo feedback, which places the outside world (or some network structure that is closer to the outside world) directly in the signaling feedback path.
This type of "servo-feedback" is shown graphically in figure 6-5 of the book, which has been re-produced here.

[Read more...]
Monday, August 23. 2010
As a programmer I find it very satisfying when a phony false choice is taken down. Chris Chatham, who maintains Developing Intelligence blog looks like he's hot on the trail of one.
In his post titled: Neural Mechanisms Giving Rise to Diffuse-to-Focal and Local-to-Distributed Developmental Shifts he has provided a run-down of some of the best observational support showing evidence for the diffuse to focal shift. He then explores and teaches some evidence for the local-to-distributed shift, which, it turns out, is just as convincing.
He provides a very good explanation for the apparent disagreement in the experimental data. His conclusion? The two aren't mutually exclusive. (thank you Mr. Chatham)
So, how does this work? Is the brain just big enough to accommodate two different mechanisms? Possibly, but Chatham also explores a distinct possibility that the same underlying mechanisms may be responsible for both types of development. It turns out there is a bit of good reason to think it is the latter.
Tuesday, August 17. 2010
The following excerpts from Chapter 4 of the book ("Our Metaphysical Tool Shed") may help to clarify the point of this post.
Anti-Razor1
It would probably be sufficient to simply express the weighted result as a ratio, but for now that's just one option. As our understanding grows, we may find that our maintaining two separate sums and many of the other values, is the metaphorical equivalent of gluing feathers to the wings of a flying machine. . .
. . .
1. This sub-heading is a reference to Ockham's razor, which is almost always mis-characterized in common usage. William of Ockham's original advice is based on sound, logical, reasoning, while the common mis-characterization is essentially a fashion statement. Here, however, I argue that programmers must give experimenters the ability to define their own (real) razors, and so should not mandate them in the modeling tools we provide. That is, we should give experimenters more, and let them decide for themselves how to divide and conquer those “more” into “fewer”.
Many of the ANN modeling tools available today are merely paint-by-number kits, which allow experimenters to try out solutions that other people have worked out and documented in formulaic recipes. Netlab is decidedly NOT among these offerings.
The known neural network formulas, for example, each represent somebody else's abstraction, and reduction of the observation data. The function produced is essentially a workable, defined, recipe for creating an effect that is similar to observed behaviors. In short, the person who came up with the formula in the first place was the one who did all the heavy lifting.
Experimenters should be given tools that let them find and test their own theories, and their own ways to pair down and represent what they think is most essential about what's going on in the problem space.
To state it simply, Netlab is built on the proposition that experimenters should be able to try out their own ideas, and not merely find new ways to use other people's ideas.
One very good way for a programmer to achieve such a goal in his design, is to reverse engineer the existing formulas. That is, for each existing formula, produce a simulation environment that would allow somebody to create the formula for the first time, were it not already known. This is one of the design philosophies underlying Netlab's software specification.
To this point it has been a rather abstract post. What follows is mostly a list of links into the glossary (I think). Now that the I.P. protection is starting to come through, I'll be able to describe this stuff more openly, and more deeply. As new documentation becomes available I'll either try to update this section with links, or copy this section into a more complete discussion of the practical mechanisms provided for achieving the simple goal described above.
- Chemicals
One of the abstractions provided by Netlab is the notion of chemicals. Neurons, beside producing output values on their axons based on a variety conditions (direct and indirect), are also capable of producing chemicals. The chemicals, much like the axon-level, can be specified to be produced in various concentration-levels based on a variety of environmental factors. The factors that lead to the production of a chemical are specified by the designer and can include stimulus on the neuron's synapses by other axons, other chemical influences in the vicinity of the neuron, or globally present chemicals (among many other factors). To specify a new chemical the designer simply comes up with a name for it.
No characteristics are explicitly specified for a given designer-named chemical. The properties and characteristics of any given named chemical are purely a biproduct of how other objects in the environment (usually other neurons) have been specified to respond/react to them. Responses to any given chemical can be different for different individual instances of a neuron, or for different classes of a neuron (this is simplified, "neuron" is really "object" and can include other super-types besides neurons),
- Spacial and Temporal Distances
Netlab's description language provides a way to modularize the design and construction of neural networks. It allows experimenters to produce components, called "units", which contain other components, such as neurons and previously designed units.
The modular construct used to overcome complexity at design time, is preserved in the Netlab run-time, giving Netlab's networks an abstraction of volumetric space, which can be used as a framework when representing both spacial and temporal phenomena.
- Pathfinding
Once you have a viable abstraction for representing temporal and volumetric chemical gradients, you can then begin to define all kinds of useful mechanisms based on the influence (e.g., repulsive or attractive) your chemical concentrations have on them. For example, like all neural network packages, Netlab includes the traditional Latent Connections. These are the static connections you determine at design time. Whether or not they actually develop is based on changes to their strengths, but the connection will always be between the same two neurons, which were specified at design time.
Netlab is able to go farther, allowing designers to specify Receptor Pads which are areas on a neuron's synapse-space that can make connections with any other neuron in the network while it is running. Other neurons put out something called a growth cone. Among other things, dynamic connections are facilitated at run time based on affinities or aversions to named chemicals specified for both the growth-cones, and the receptor pads. This allows, for example, a given class of growth cone to be defined to "desire", "seek-out", and "find" its perfect receptor pad, dynamically, as the network runs. It is good to mention again here, that chemicals influencing these movement decisions by growth-cones are also being produced dynamically, and their concentrations will be based on factors that are products of the running network within its dynamic environment.
- No Limits On Feedback
A new patented learning method has been developed that completely eliminates past restrictions placed on types or amounts of feedback employed in the structure of the network. Beside just being great for general feedback that may want to span multiple local loops at times, this is also very nice for servo-structures, which put the outside world directly in the feedback path. This allows for representing the outside world as a the correction-factors that must be adapted, in order to correct for outside forces. In essence, the world's complex and chaotic stimuli become a transfer function that sits directly in the network's feedback loop. The network, then performs the function of correcting for inconsistencies in the feedback function, which it can then learn.
Thursday, August 12. 2010
A recent USC study applies a new technique that allows researches to more closely map the brain's wiring. One goal of the study is to better clarify our current understanding of the connection-structure of brains. Also, to try and settle the raging "It's an internetwork" / "It's a hierarchical pyramid" debate.
The Netlab abstraction is designed to facilitate a similar, but slightly different concept of brain wiring-structure, which is visually depicted in the cover art of the book:
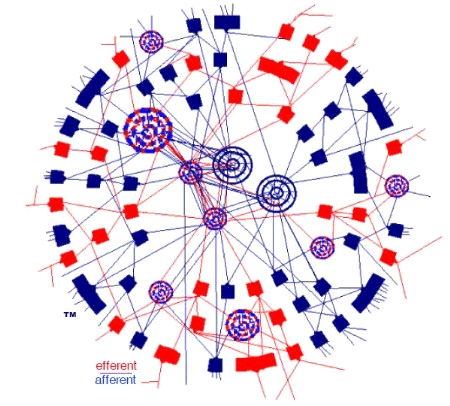
Any Connectome You'd Like No 1
Netlab's idealized wiring-structure requirement (simplified)
The above diagram should be seen as a cross-section through a sphere, so the word "donut" in this entry-title takes some license. The interior/exterior connection-model, as depicted, does seem to find—at least passing— observational support in the USC study, e.g.,:
"The circuits showed up as patterns of circular loops, suggesting that at least in this part of the rat brain, the wiring diagram looks like a distributed network."

-djr
Monday, May 17. 2010

|
There they go again...
The marketeers are always working feverishly to persuade us of our absolute need for whatever "next-big-thing" they think they can convince us to buy.
It turns out, however, that memristors don't really need the market-speak and the sokalisms from the persuasive-arts crowd. Memristors really are extremely useful, and will almost surely bring about some seriously cool changes in the technological world.
|
[Read more...]
Monday, April 26. 2010
The improvements and innovations are coming fast and furious now. It is a great time to be into this stuff.
Traditional fMRI (it is strange to type that) detected blood flow. Hemoglobin in blood contains iron, which mediates changes in magnetic fields. These are, in turn, detected and converted to three-dimensional image data by the MRI. That same iron-containing molecule carries oxygen to the cells of the body. When neurons become more active they require more oxygen-carrying blood. Arteries in the vicinity of the active neuron cells respond by dilating in order to increase the supply. It is this extra blood that is detected by fMRI (traditional fMRI, that is).
This has been a boon to understanding the topographical correlates of thought and brain function. That's the upside. The downside is that it produces very course correlates. That is, it only measures increased blood flow in the vicinity of neural activity. It doesn't pin-point the actual activity topographically.
It is also contextually course information. In other words, it displays all activity, and can't discern between, say long-, and short-term PTP, or any of the staggering number of other protein interactions that are involved in different types of mental activity. These different types of activity are often as important as locational activity.
Finally, it has a course temporal aperture as well. Because it measures blood-flow, it tends to see the activity many milliseconds, or even seconds after the activity has started
Some of the timing and delay deficiencies have been overcome by coupling it with EEG scans as well. EEG scans have almost no positional information, just giving general areas of the brain where electrical activity is sourced, but it does give immediate feedback, which can then be narrowed by the fMRI imaging that comes in some time later.
Now, the researchers at MIT have begun to work on new ways for the fMRI to image actual protein/neurotransmitter mediated activity in the brain. Instead of simply measuring the amount of activity through increased hemoglobin in the area, these will image on the actual molecules involved in brain functions. They are accomplishing this by coming up with contrast agents (things that make an MRI image brighter or darker), which bind directly to the various molecular sites and chemicals in the brain used in brain and neuron function.
The upshot? Faster, more tightly synchronized time windows, more fine-grained spacial resolutions and magnification scales, and a whole new dimension of functionality. The functionality is based on being able to contrast specific molecular mechanisms having to do with specific types of brain activity.
Monday, April 5. 2010
In 1992 two men were awarded the Nobel Science Prize in Physiology or Medicine for work that is proving extremely important to our understanding of brain function at the cellular and molecular levels.
The 1992 prize went to Dr.s Edmond H. Fischer and Edwin G. Krebs for their research and discoveries of “reversible protein phosphorylation as a biological regulatory mechanism.” (i.e., glycogen phosphorylase).

Dr. Edmond Fischer
|

Dr. Edwin Krebs
|
Just a hunch, but I bet people get their names conflated every which way.
|

|
 Stand Out Publishing
Stand Out Publishing