Stand Out Publishing
Stand Out Publishing
|
|
|
About:
Exploring new approaches to machine hosted neural-network simulation, and the science behind them.
Your moderator:
John Repici
A programmer who is obsessed with giving experimenters a better environment for developing biologically-guided neural network designs. Author of an introductory book on the subject titled: "Netlab Loligo: New Approaches to Neural Network Simulation". BOOK REVIEWERS ARE NEEDED! Can you help?
Other Blogs/Sites:
Neural Networks Hardware (Robotics, etc.) 
|
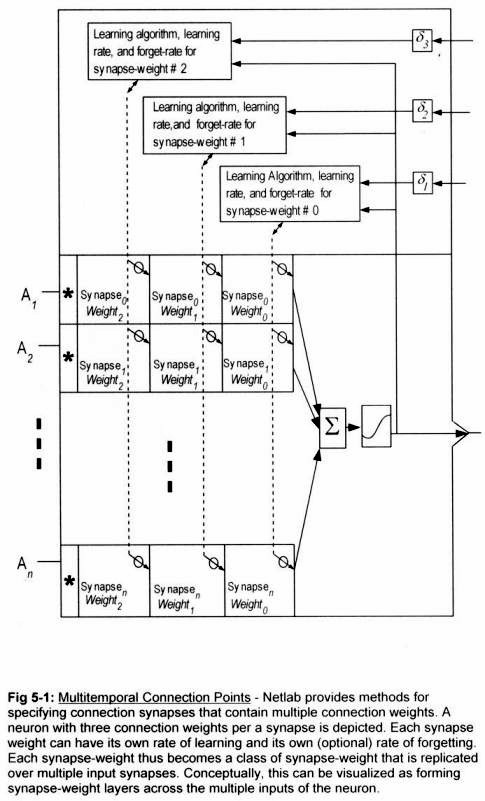
Wednesday, January 26. 2011Introducing: Multitemporal Synapses
A set of constructs and methods introduced and described in the book: Netlab Loligo will improve the ability of systems constructed with them to adapt to current short-term situations, and learn from those short-term experiences over the long term.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

|
Woo HOOO!Influence Based Learning, one of two new learning methods described in the book Netlab Loligo, has just been awarded a United States Patent. The official title of the patent is: The title is a mouthful, primarily designed to help future patent searchers determine if their great idea has already been discovered and patented. It is fully described and discussed in the book, where it is simply referred to as Influence Learning. As the patent-title expresses, one of the benefits it imparts over existing learning algorithms, is that it is feedback-tolerant. It will work fine with the current-day feed-forward networks configured as "slabs", but it also allows connecting neurons to pre-synaptic neurons as well. That is, it allows feedback, which means you don't have to configure your network with "hidden layers" anymore if you don't want to. You are free to use any connectome you'd like. |
|
|
April '24 |
|
||||
| Sun | Mon | Tue | Wed | Thu | Fri | Sat |
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
Exploring new approaches to
machine hosted neural-networks,
and the science behind them.




 ). The patent is titled:
). The patent is titled: